
DATABASE TESTING INTERVIEW PART-4
Please go through the most frequently asked database testing interview topics.
sub-query
A sub-query is also called as a nested query.
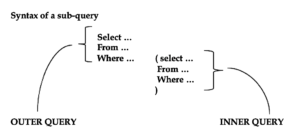
Here, the inner query will be executed first.
INNER QUERY
The output of inner query is passed as input to the outer query.
To write a sub-query, at least 1 common column should be existing between the tables.
For example:-
1) List the employees working in the ‘Research’ department.

2) List the department names that are having analysts
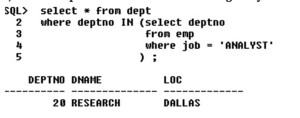
3) List the employees in Research and Sales department
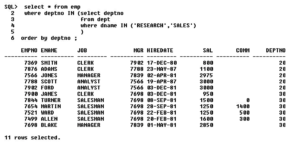
Try to solve:
1) List the department names which are having salesmen in them.

2) Display the employees whose location is having at least one ‘O’ in it.
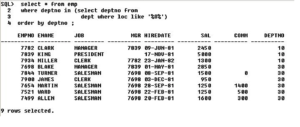
3) List the department names that are having at least 1 employee in it.
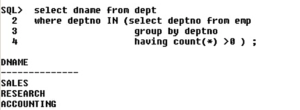
4) List the department names that are having at least 4 employees in it
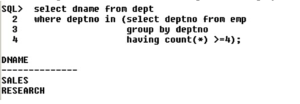
5) Display the department names which are having at least 2clerks in it
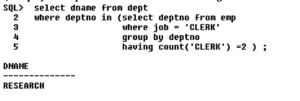
6) Display the 2 maximum salary

7) Display the 3 maximum salary

8) Display the 4 least salary
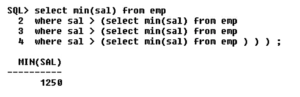
This method is not efficient to find the maximum and minimum salary. The limit is 32. This is not the efficient if you want to find the 100 maximum salary. We can have up to 32 levels of sub-queries only.
9) List the department names that are having no employees at all

Joins
Joins are used when we need to fetch the data from multiple tables
Types of JOIN(s)
- Cartesian Join (product)
- Inner (Equi) Join
- Outer Join – Left Outer Join, Right Outer Join, Full Outer Join
- Self Join
CARTESIAN JOIN
– It is based on Cartesian product theory.

Here, each and every record of the 1 table will combine with each and every record of the 2 table.
If table A is having 10 records & B is having 4 records – the Cartesian join will return 10*4 = 40 records.
For example, let us consider the following query
Display employee name along with the department name

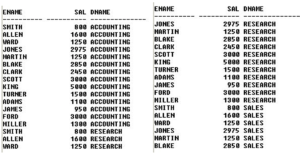

From the above – we can see that the above query returns 56 records – but we are expecting 14 records. This is because each and every record of employee table will be combined with each & every record of the department table.
Thus, Cartesian join should not be used in real-time scenarios.
The Cartesian join contains both correct and incorrect sets of data. We have to retain the correct ones & eliminate the incorrect ones by using the inner join.
INNER JOIN
Inner join is also called equijoins.
They return the matching records between the tables.
In real-time scenarios, this is the most frequently used Join. For example, consider the query shown below,
Select A.ename, A.sal, B.dname From emp A, dept B – – JOIN condition
Where A.deptno = B.deptno And A.sal > 2000 – – FILTER condition
Order by A.sal ;
Let us see the output shown below,
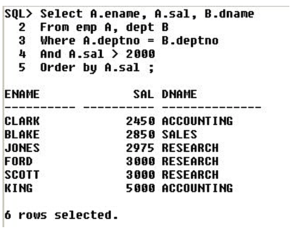
JOIN condition is mandatory for removing the Cartesian output.
Let us consider the following 2 scenarios shown below,

![]()

If there are no common columns, then reject it saying that the two tables can be joined.
But there are some cases – where the 2 columns will be the same but have different column names. For example – customer id & cid
Display employee name, his job, his dname and his location for all the managers living in New York or Chicago

ANSI style JOINS
This was introduced from Oracle 9i.
It is another way of writing inner joins with a few modifications

Thus we can see the changes,
- In the 2nd line – ,(comma) has been replaced by the word ‘join’
In the 3rd line – ‘where’ has been replaced with ‘on’
Assignment
1) Display employee name and his department name for the employees whose name starts with ‘S’
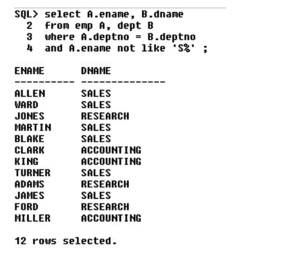
OUTER JOIN
It returns both matching and non-matching records
Outer join = inner join + non-matching records
Non-matching records mean data present in one table, but absent in another table w.r.to common columns.
For example, 40 is there in deptno of dept table, but not there in deptno of emp table.
Display all the department names irrespective of any employee working in it or not. If an employee is working – display his name.
Using right join
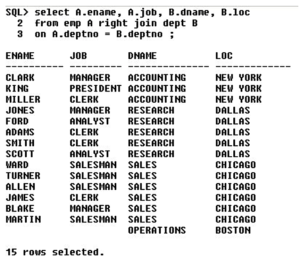
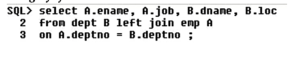
Using left join
Using full join
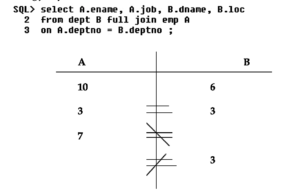
A CJ B = 60records
A IJ B = 3records(3 matchings)
A LJ B = 10records (3matching + 7non matching of A)
A RJ B = 6records (3matching + 3non matching of B)
A FJ B = 13records (3matching of A & B + 7nonmatching of A + 3nonmatching of B)
Assignment
1) Display employee name and his department name for the employees whose name starts with ‘S’

2) Display employee name and his department name who is earning 1 st maximum salary.

SELF JOIN
Joining a table to itself is called self-join
The FROM clause looks like this, FROM emp A, emp B
FROM emp A join emp B – ANSI style
For example, – Display employee name along with their manager name
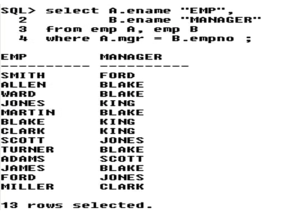
Now, let us see how this i.e the logic (the above query) works,
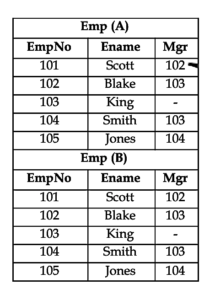
Now, when we give the above query – in Oracle – it starts matching the ‘mgr’ column of emp A with the ‘empno’ of emp b – we get two tables because in self join – a duplicate of the table required is created.
Now let us consider the first employee Scott – it starts the mgrid of Scott with the empno of all the records in emp B – when two ids match, then the empno in emp B becomes the mgr of the empno in emp A. Thus, we can see that – mgr id 102 is matching with empno 102 Blake in emp B. Therefore, Blake is the manager of Scott.
Similarly, we do the same for all the other records of emp A and thus find the employees and their respective managers.
Display the employees who are getting the same salary
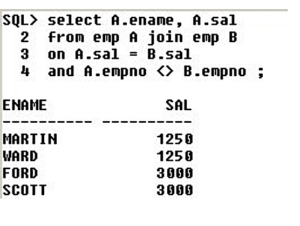
Co – related Queries :
They are a special type of subqueries
Here, both outer & inner queries are inter-dependent
For each & every record of the outer query, the entire inner query will be executed
They work on the principles of both subqueries & JOIN(s).
For example, Display the employee who is earning the highest salary

Thus, if an outer query column is being accessed inside the inner query, then that query is said to be co-related.
Let us see the logic i.e, how we get the 1st max salary:-
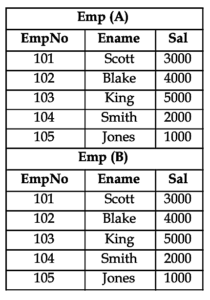
Since co-related queries are a combination of joins and sub-queries.
It follows the concept of Joins and creates multiple copies of the same table.
Then it takes 1st record i.e, – Blake – sal is 3000. It starts comparing with the sal in the emp table,
3000 = 3000 – count starts from 0 – thus, 0 = 0
3000 < 4000 – thus, 0 ! = 1
3000 < 5000 – thus, 0 ! = 2
3000 > 2000 – thus , 0! = 2
3000 > 1000 – thus, 0 ! = 2
if the condition becomes false, then the count increments by 1. Here 3000 is less than 4000 & 5000, thus 0 ! = 2. Thus , Blake does not have the highest salary.
Similarly, it does for the next records,
Blake – salary of 4000 – but 4000 < 5000 – thus, 0 ! = 1. This is also false.
King – salary of 5000 – it is greater than everything – thus, 0 = 0. Thus, King has the highest salary. But the query doesn’t stop here, it checks for Smith & Jones as well.
Similarly, if we want to find the 2nd maximum salary,
Then in the query, change ‘0’ to ‘1’ & here, the logic is – it compares until it gets 1 = 1.
For 3rd maximum salary – change 0 to 2 and so on – here, the logic is – it compares until it gets 2 = 2.
For any highest, always put it as ‘0’ in the query.
If you want n(th) salary, pass (n-1).
In the interview – this is a definite question. They will ask you what is co-related queries. And then they’ll ask you find, 1st or max or 3rd maximum salary – after you write the query – they will ask you to explain the logic as to how it gets the same – draw the table and explain it to them just as shown above.
Example:
1) Display the least salary from the employee table.

Functions
Functions – it is a re-usable program that returns a value.
There are 2 types,
- Predefined
- User-defined
Predefined
→ GROUP functions
→ CHARACTER functions
→ NUMERIC functions
→ DA TE functions
→ SPECIAL functions
These are used both in SQL and PL/SQL. PL – Procedural Language (it’s an extension to SQL, can contain IF statements, loops, exceptions, OOPs, etc .. )
User-defined
Used only in PL/SQL and we will not study it here.
CHARACTER functions
Now, let us study the various CHARACTER functions.
CHARACTER functions
- Upper
- Lower
- Length
Dual – is a dummy table that is used for performing some independent operations which will not depend on any of the existing tables.
We use dual – when the data is not present in any of the existing tables. Then we use dual.
Length – it returns the length of a given string.
REPLACE
It replaces the old value with a new value in the given string.
SUBSTR
This is called substring.
It extracts ‘n’ characters from x(th) position of a given string.
INSTR
This is also called as instring.
It returns the position of a given character in a given string.
CONCAT
It concatenates any two values or columns. It is represented by – ||
NUMERIC FUNCTIONS
1) Mod :- it returns the remainder when 1 number is divided by the other.
2)Round:- It rounds off a given number to the nearest decimal place.
3) Trunc:- It truncates the given number to the given decimal place. Truncate does not do any rounding.
DATE FUNCTIONS
1) Sysdate
Stands for System date.
It returns both date & time, but by default – only date is displayed. The default format is,
dd – mon – yy
2) Systimestamp
Introduced from Oracle 9i Returns date, time, and timezone.
In the interview – if they ask you – “ which function contains fractions of a second “ OR “how to see the system time “ – then answer is “SYSTIMESTAMP”.
SPECIAL FUNCTIONS
1) TO – CHAR
Used for displaying the date in different formats.
2) NVL
It substitutes a value for a null.
3) DECODE
It works like ‘if – then – else’ statement.
Normalization
Normalization is the process of splitting the bigger table into many small tables without changing its functionality.
It is generally carried out during the design phase of SDLC.
Advantages
1) it reduces the redundancy (unnecessary repetition of data)
2) avoids problem due to deleting anamoly (inconsistency)
Normalization is a step-by-step process and in each step, we have to perform some activities.
STEPS IN NORMALIZATION
1) 1NF – 1st Normal form
2) 2NF – 2nd Normal form
3) 3NF – 3rd Normal form
1NF
- We should collect all the required attributes into 1 or bigger entities.
- We have to assume no 2 records are the same (i.e, records should not be duplicated)
- Identify the probable primary key
At the end of 1NF, our data looks like this,

2NF
To perform 2NF,
- The tables have to be in 1NF
Here, we identify all the complete dependencies and move them separately into different tables.
At the end of 2NF, our data looks like this,
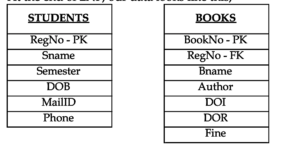
3NF
The table will have to be in 2NF
Here, we identify all the partial dependencies and move such columns to a separate table.

Disadvantage of Normalization
The only minor disadvantage is we may have to write complex queries as we have more tables to be accessed.
Denormalization is the process of combining more than 1 smaller table to form 1 bigger table is called denormalization.